Wikipedia is, indeed, one of the largest free access crowdsourcing [1] sources of information in today's world. Every day, thousands of people land on its pages to get information about different topics. Moreover, many machine learning algorithms (including text mining, semantic web, etc.) get their input from Wikipedia; for example, Google’s Knowledge Graph is mainly built around Wikipedia [2].
Every day, different news articles are published in different news media. Among them, only a few attract significant attention from the public. The media refers to these stories as “hot news.” Usually, within a news organization, experts decide if news is hot or not. Of course, they use their own domain knowledge and other sources, such as the number of “likes” an article receives on Facebook or the number of retweets on Twitter, to decide whether a story is hot or not, yet in the data-driven world, from which we derive many metrics, this is not a scalable, automated approach. As data scientists, we love to find these things in data and decrease the role of humans in the analytic process (creating humanless analyses, if you will).
This is the goal of this post. Here, I show how we can use the number of Wikipedia article page views to determine if a news story is hot. This approach is fully data-driven and does not need any human supervision.
Intuition:
To understand intuition, think of a time when you have read a news article. If the news is interesting to you, you might like to dig a little more into it. You might read more about its history, or search for a more in-depth description. Hence, you will perform a search about the topic. Therefore, interesting news can be said to be marked by increasing search trends. In other words, as a news item starts to attract more attention, the number of searches on topics related to that subject will increase accordingly.
Clearly, a subsample of those searches will land on a Wikipedia page. Wikipedia articles are the main source many people use to read more about a topic. This means, the more people who perform a search on a topic, the more visits there will be to Wikipedia pages related to that topic. Let’s look at some examples.
Examples:
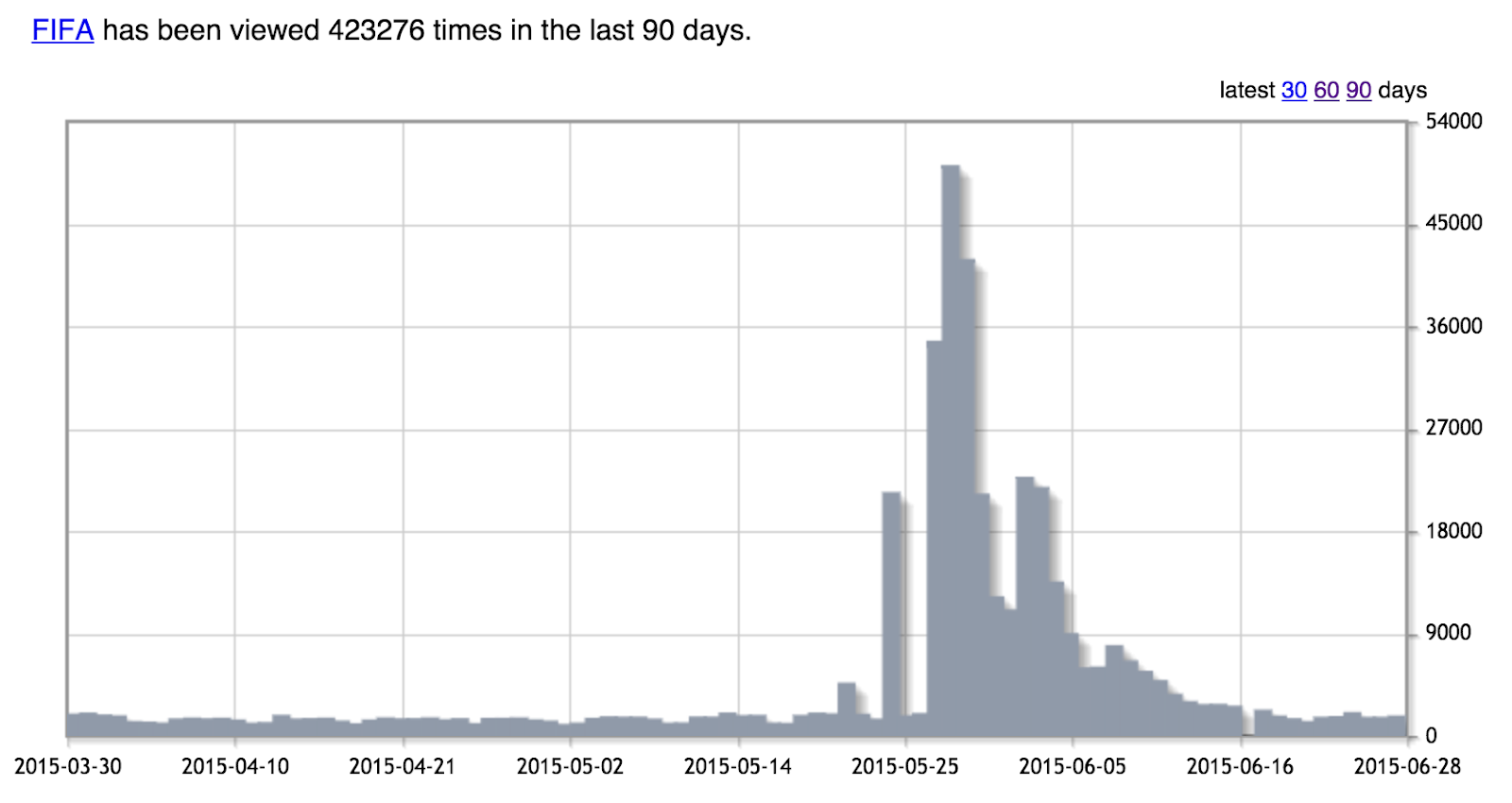
You may have heard about recent charges of corruption in the FIFA organization. The following plot shows the daily views to FIFA Wikipedia’s page in the last 90 days (as of June 28, 2015). Clearly, around May 25th, there was an upward trend of access to the page. Why? That was the date when the corruption news became “hot.”
As of this writing, the US Supreme Court has declared same-sex marriage legal [3]. Let’s look at page visits to a Wikipedia page on same-sex marriage.
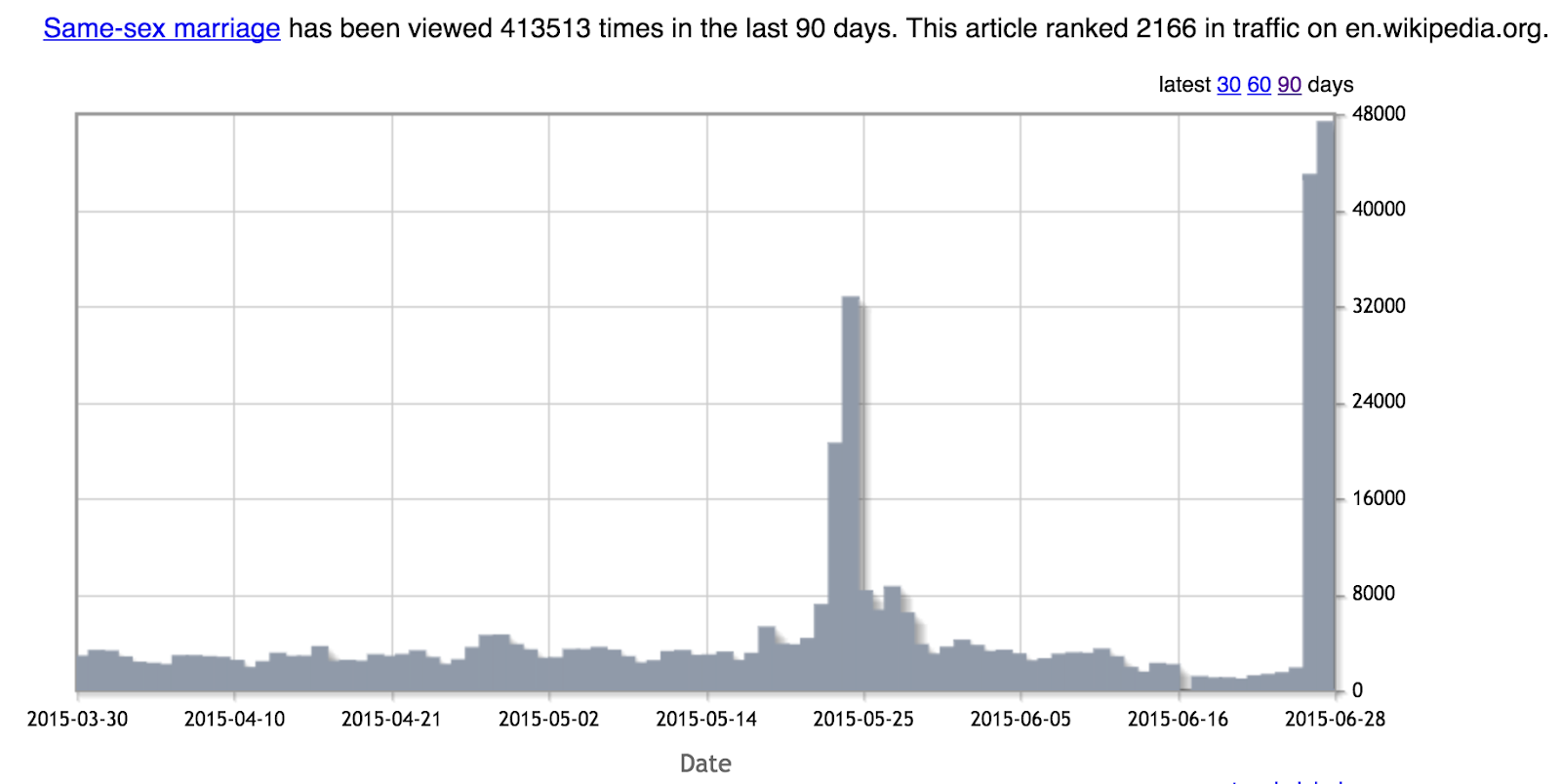
There is no doubt that this topic has received a great deal of attention, and the data proves that this is a hot news item. As the chart above indicates, the number of page visits has gone from around 1000 per day to around 50,000 in the last two days alone.
Hot news detection:
With the above intuition and examples, hot news detection using Wikipedia page access seems fairly straightforward. First, we need to have the page view counts for Wikipedia pages. Then, we can create a page view history for every page. Next, for each page, we use a simple trend change detection algorithm to detect if the access trends related to that page are increasing statistically. If so, we can infer that the page contains a topic related to a hot news item.
In other words, data-driven hot news detection using Wikipedia contains four steps:
1- Download the dataset
Wikipedia provides the page view statistics for all of its articles, and these are publicly available [4]. This data can be downloaded here:
2- Create a history for pages
There are almost 5 million Wikipedia articles in English. Although this is a huge amount of English-language content, the statistics regarding the pages can easily fit into couple of hundred megabytes of memory. Hence, we can easily create a 90-day page view history for all English language Wikipedia articles.
3- Detect any trend (increasing) changes in page access
Now that we have the page view history for the Wikipedia articles, we just need to use a trend change detection algorithm to find pages that are receiving more visits now compared to their history. I have a separate blog post on this:
4- Newslookup
After I find the top pages in terms of changes in their access rates, I use the newslookup.com search api to find news that is correlated to these pages. These news stories are the hot news items that we have been looking for.
5- Open source R program to detect hot news
The R program that does all the above can be found on my github page [5]. Please note that this program detects hourly hot news. If you would like daily hot news, or even weekly hot news, you simply need to change the aggregate function.
As a Service [Updated July 29]
This technique is available as a web service. It provides both the hot news in the past X hours and the hot wikipedia pages (with increase trend) in the past 48 hours. Please refer to http://hotnews.ask-tell.info/howto.html for more information about how to access the service.
The hot stories that are found using this technique is fed to a twitter channel: @EyeWikiNews. You can follow it and stay tune with top news in the world.
[1] It seems that Jimmy Wales does not like the term crowdsourcing for Wikipedia: http://www.sfgate.com/business/article/As-Wikipedia-moves-to-S-F-founder-discusses-3233536.php